Bias and Variance
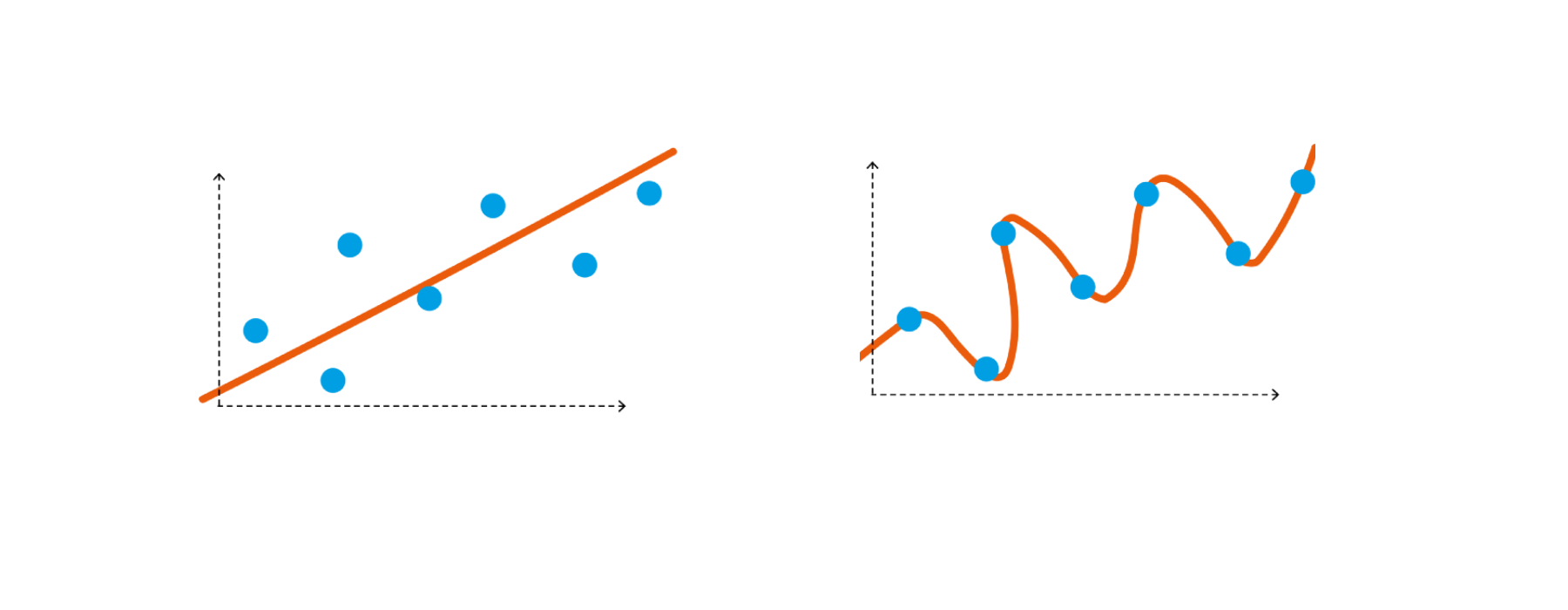
Bias
Bias is the inability of the model to establish true relationship between features and tanget variable
So let's understand this with an example - Consider we have scattered some pens and pencils on the bench. If you try to separate out these pens and pencils with stick then it might get difficult for you to decide how to place that stick
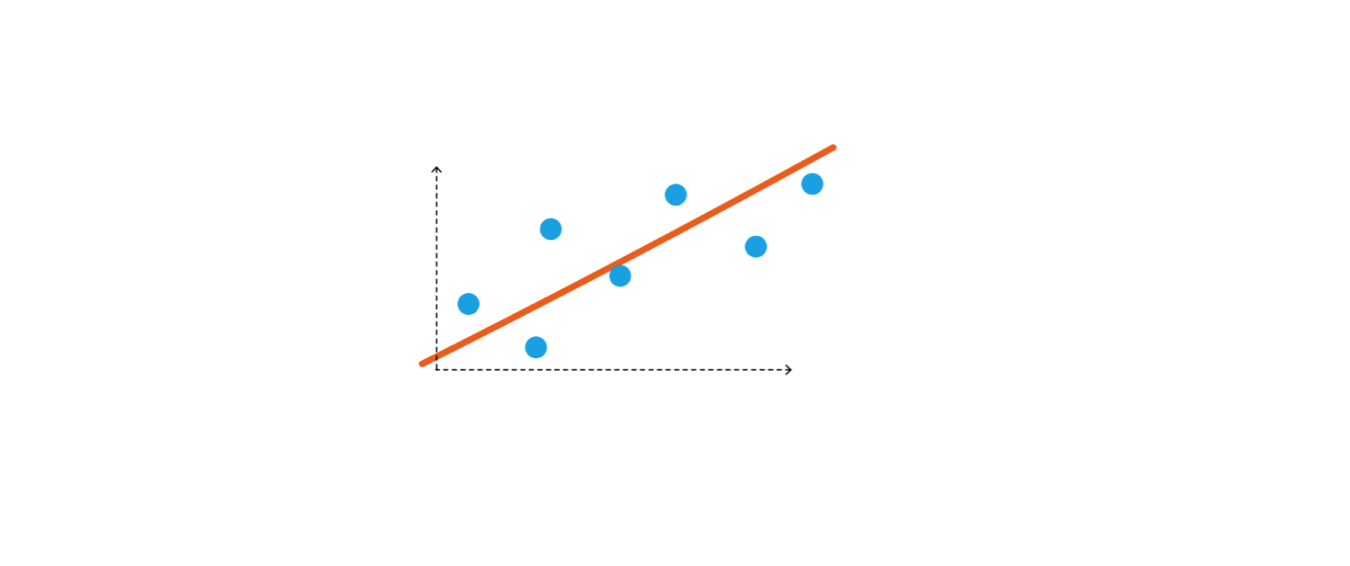
You can say that there is an inability to establish a true relationship between stick and pens or stick and pencils. Even if you try to do that the performance will be low. Hence you can say that it is underfitter or highly biased towards the assumption that you made while placing the stick.
In an ideal world we want low bias. Low bias means model is able to establish the true relationship between dependent and independent variable
* Low Bias: Low bias value means fewer assumptions are taken to build the target function. In this case, the model will closely match the training dataset.
* High Bias: High bias value means more assumptions are taken to build the target function. In this case, the model will not match the training dataset closely.
Ways to reduce high bias in Machine Learning:
1. Use a more complex model
2. Increase the number of features
3. Reduce Regularization of the model
4. Increase the size of the training data
Variance
Variance is difference in fits between datasets
Let’s consider the same example but now we will try to differentiate the pens and pencils with a thread instead of a stick. Now we don't make many assumptions right ?
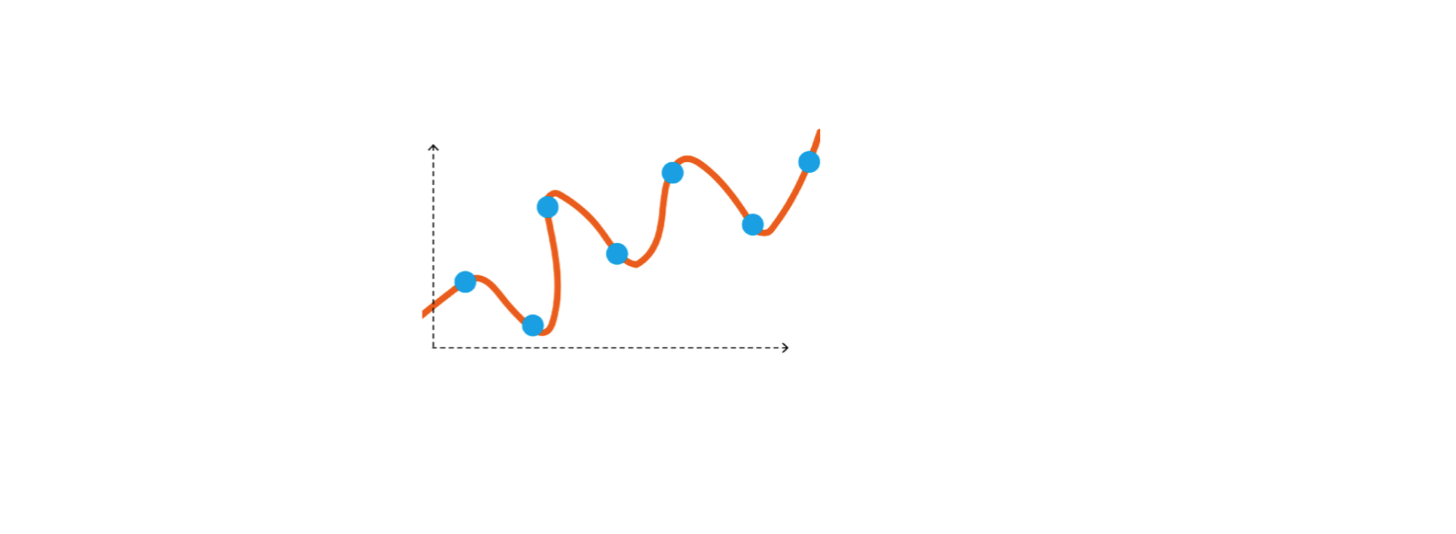
We place thread in such a way that we differentiate these pens and pencils with maximum capability. So model performance very well. But what happens if we throw more samples (pens & pencils ) on the table ? We realize the thread is over fitted for the previous samples.
Hence, Stick might not be able to establish a true relationship but using the thread instead of stick will lead to overfitting. This is called bias - variance tradeoff
* Low variance: Low variance means that the model is less sensitive to changes in the training data and can produce consistent estimates of the target function with different subsets of data from the same distribution. This is the case of underfitting when the model fails to generalize on both training and test data.
* High variance: High variance means that the model is very sensitive to changes in the training data and can result in significant changes in the estimate of the target function when trained on different subsets of data from the same distribution. This is the case of overfitting when the model performs well on the training data but poorly on new, unseen test data. It fits the training data too closely that it fails on the new training dataset.
Ways to reduce high variance in Machine Learning:
1. Cross-validation
2. Feature selection
3. Regularization of the model
4. Ensemble methods (Bagging, boosting)
5. Simplifying the model
6. Early stopping
Bias Variance Tradeoff
If the algorithm is too simple (hypothesis with linear equation) then it may be on high bias and low variance condition and thus is error-prone. If algorithms fit too complex (hypothesis with high degree equation) then it may be on high variance and low bias. In the latter condition, the new entries will not perform well. Well, there is something between both of these conditions, known as a Trade-off or Bias Variance Trade-off. This tradeoff in complexity is why there is a tradeoff between bias and variance. An algorithm can’t be more complex and less complex at the same time. For the graph, the perfect tradeoff will be like this.
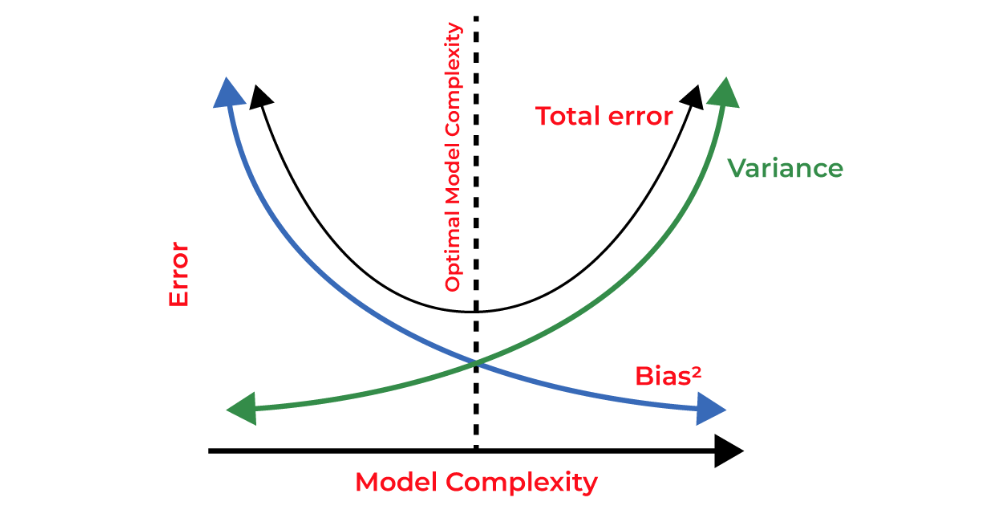
The technique by which we analyze the performance of the machine learning model is known as Bias Variance Decomposition.