How do I do it?
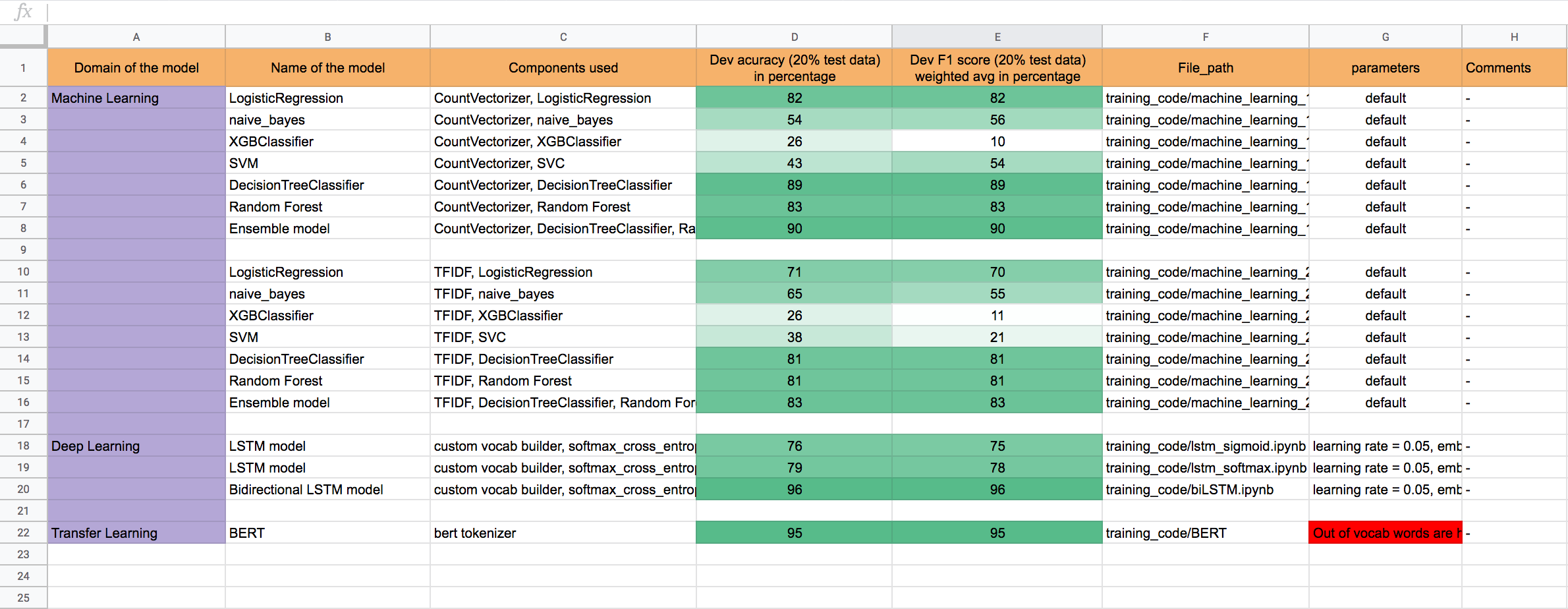
Unlike existing information extraction methods that do not consider the popularity of product attributes, the framework is not only able to detect popular product features from a collection of customer reviews but also map these popular features to the related product attributes.
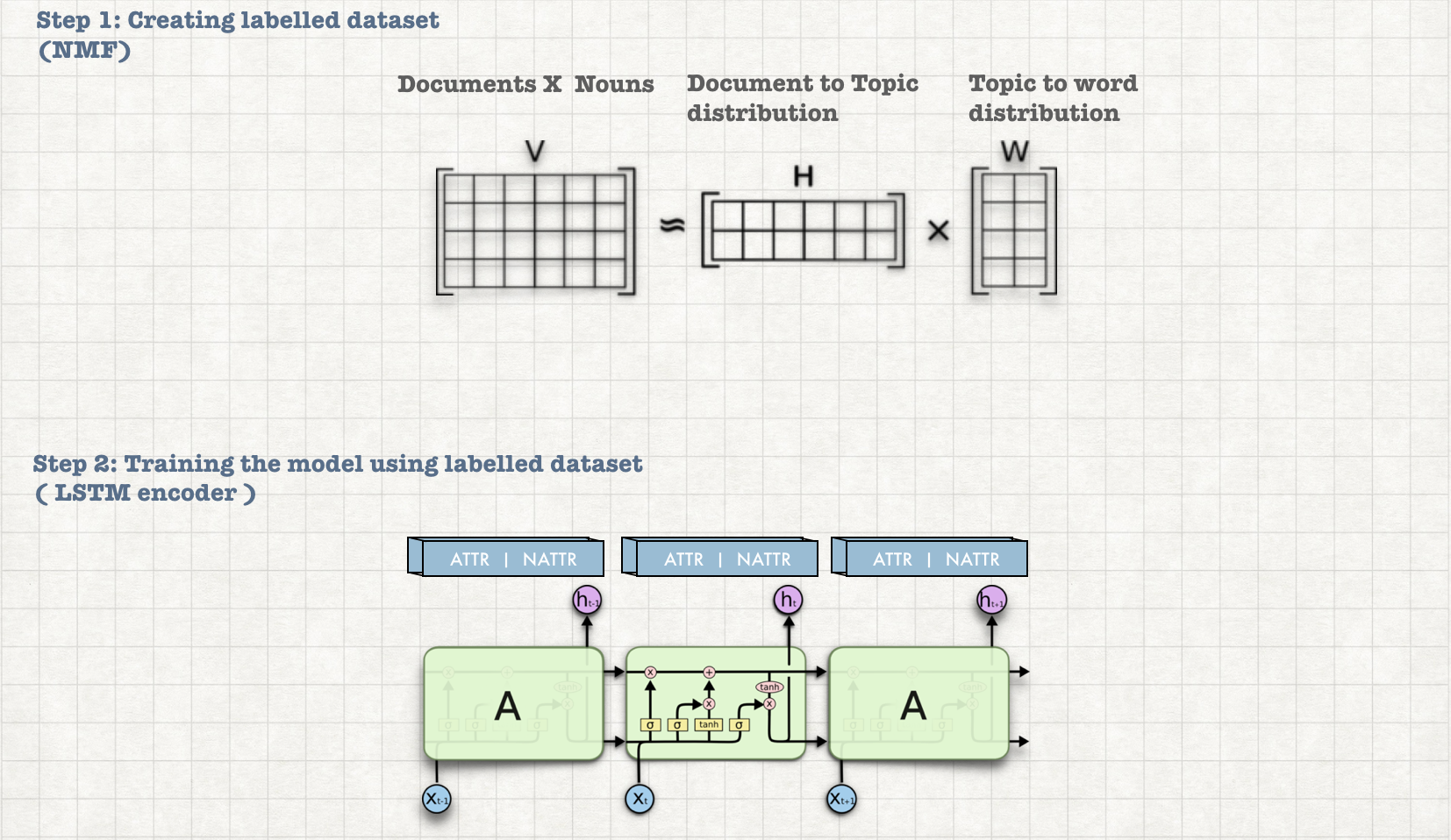
To overcome the lack of the labelled dataset (like 'Camera' is an attribute in the review "Camera of this phone is excellent") and the amount of effort involved in manual labelling the proposed method uses an unsupervised topic modelling technic inorder to label the dataset. Once the labelled data set has been created LSTM based sequence labelling model is trained to identify the attributes present in the review.
This model can be used to identify the user interests and their sentiments for those interests or attributes. For example: Given a review "Camera & Battery of this phone is good". It will identify camera and battery as attributes.
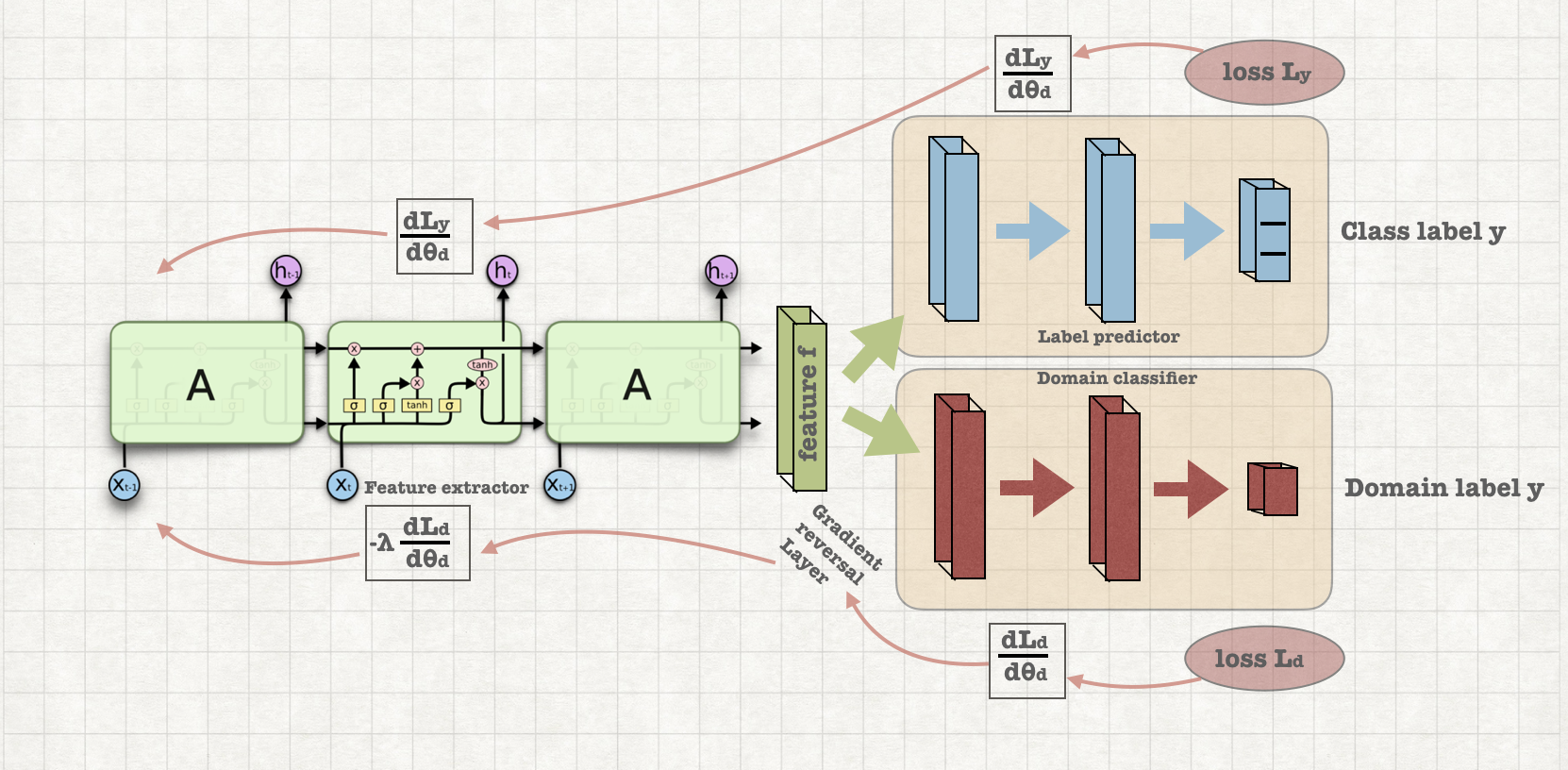
Top-performing deep learning architectures are trained on massive amounts of labeled data. In the absence of labeled data for a certain task, domain adaptation often provides an attractive option given that labeled data of similar nature but from a different domain are available.This model is used for domain adaptation in deep learning architectures that can be trained on large amount of labeled data from the source domain and large amount of unlabeled data from the target domain.
Traditional classification model cannot correctly predict for the samples drawn from a distribution that is different than training data distribution. This model overcomes that disability and shows significant improvement in accuracy.
The goal of this task is extracting brands and models from eCommerce sites' titles (such as eBay or Amazon). The same model can be used to identify the brand and model present in the youtube video titles or transcripts. This model is used to extract the brand and model across all the eCommerce pages including text pages and video pages which intern used in the Knowledge graph.
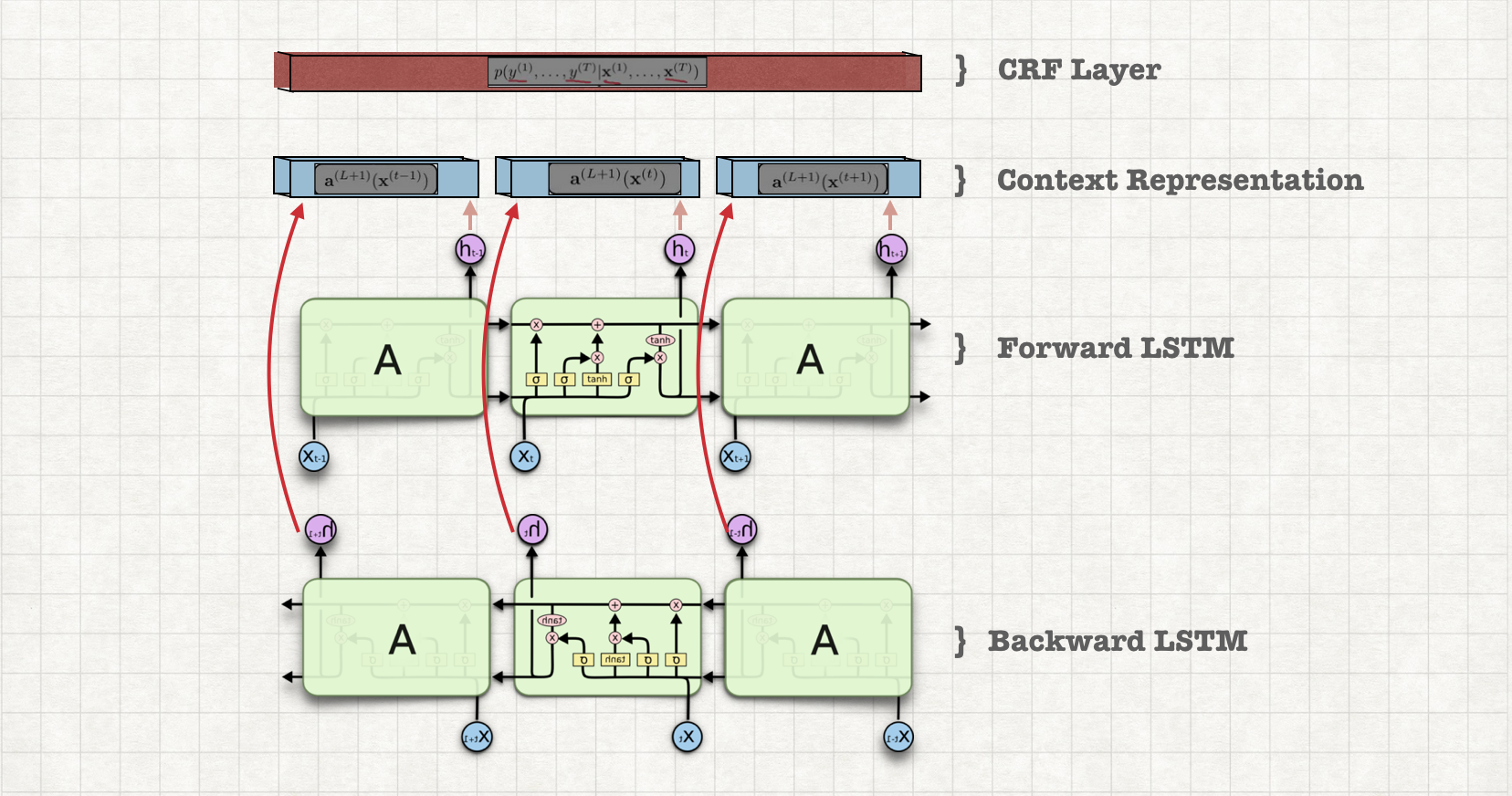
Bidirectional LSTMs and Conditional random fields are the building blocks of the model. LSTMs are used for the contextual representation. CRFs are used to classify this contextual representations into Brand and Model.
This model is one of the component of Knowledge graph created for youtube videos. In order to create the catalogue of video data, knowledge graph plays an important role and Brand & Model identification is the important component of this knowledge graph.
Sentiment analysis is an important task in natural language processing. It solves the computational processing of opinions, emotions, and subjectivity - sentiment is collected, analyzed and summarized. Aspect-based sentiment analysis (ABSA),which aims to identify fine-grained opinion polarity towards a specific aspect, is a challenging subtask of sentiment analysis.
aspect based sentiment analysis demo
Let's say there is a review "Camera of this phone is good but battery is not that great". If we use traditional sentiment analysis, the sentiment of this sentence would be neutral but where as review expresses positive sentiment towards attribute 'Camera' and negative sentiment towards attribute 'Battery'. Aspect based sentiment analysis helps us to give attribute-wise sentiments.
Recent approaches to question generation have used modifications to a Seq2Seq architecture inspired by advances in machine translation. Models are trained using teacher forcing to optimise only the one-step-ahead prediction. However, at test time, the model is asked to generate a whole sequence, causing errors to propagate through the generation process.
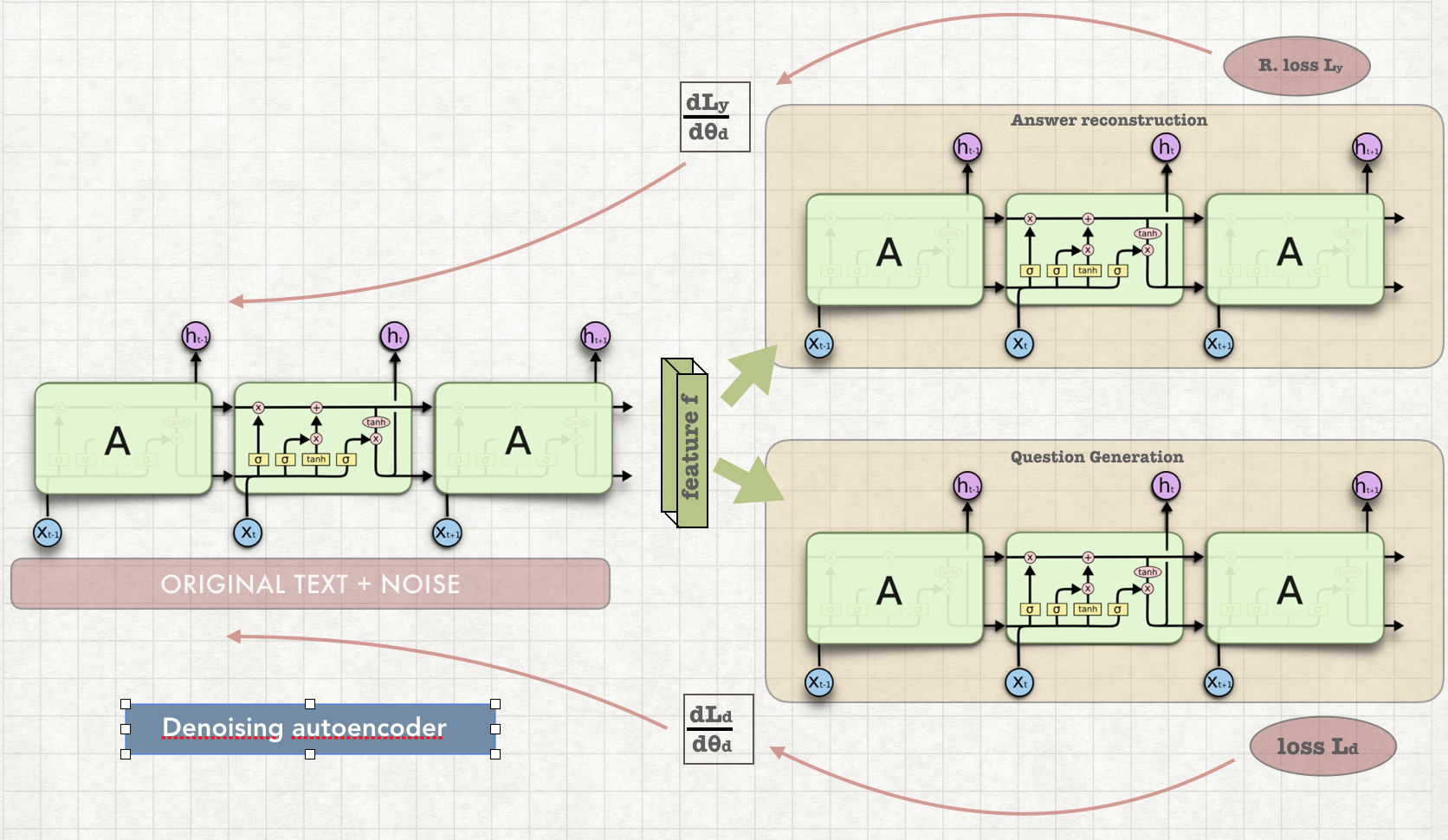
Training with policy gradient methods leads to increases in the metrics used as rewards. Posing questions about a document in natural language is a crucial aspect of the effort to automatically process natural language data, enabling machines to ask clarification questions.
Request question generation demo
This model is built inorder to generate quesions on video snippets. These question-answer snippets are placed on eComerce websites in the place of QA section. Business scope of this model is to increase user engagement on eComerce websites.
Understanding semantic relatedness of sentences would allow understanding of much of the user-generated content on the internet, such as on Quora, Stackoverflow etc. This model is used to solve the problem of actual duplication or exact semantic coincidence between questions. Solving this problem would be useful to helping Quora organize and deduplicate their knowledge base.
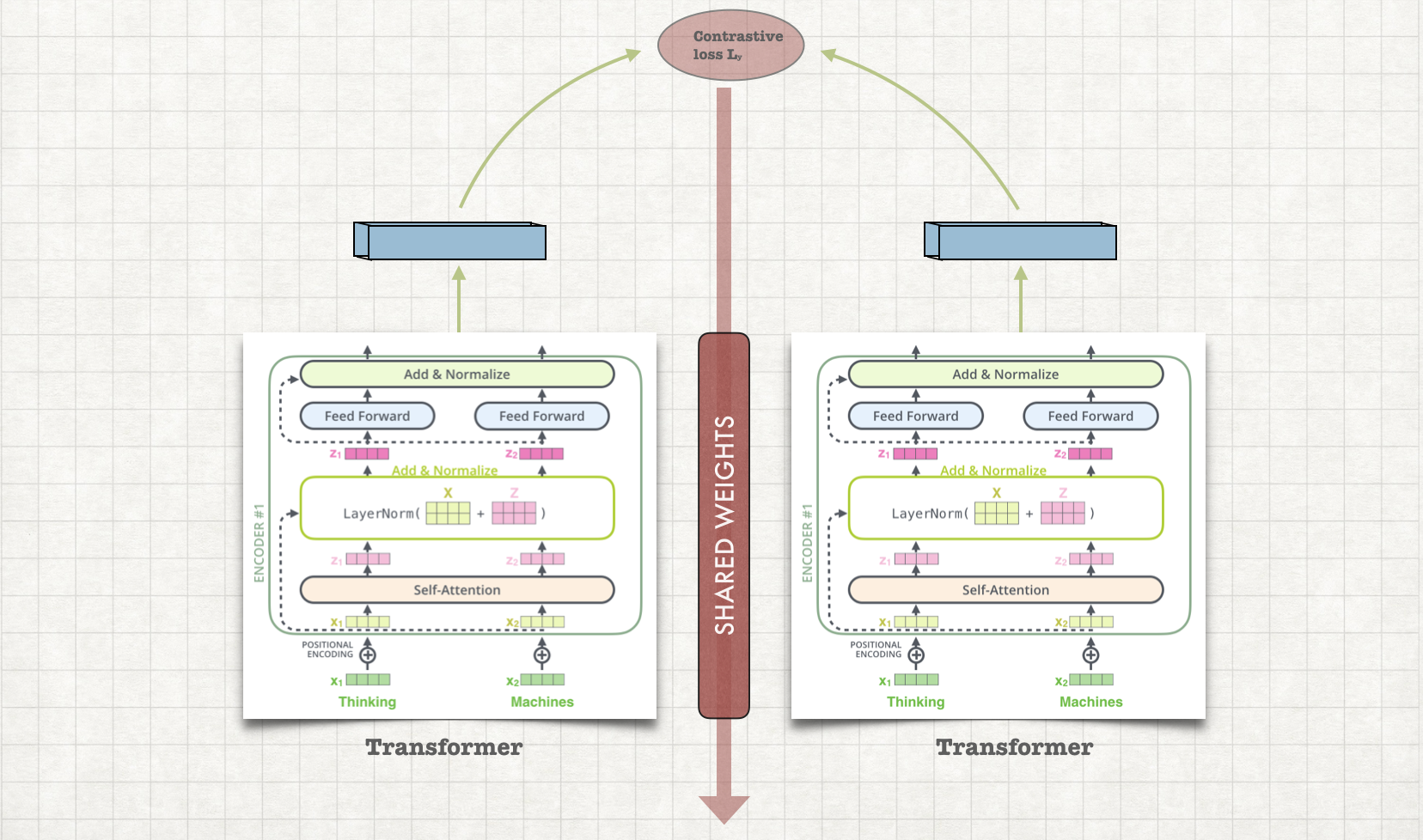
This model uses Siamese architecture to find the similar questions. Both the networks of this siamese architecture are transformers. This transformer siamese architecture is trained using contrastive loss such as hinge loss. During the training similar questions are pulled towards to each other in vector space while disimilar questions are pulled away from each other.
Request question deduplication demo
Question generation model and question deduplication models are tightly coupled. Since question generation model is an LSTM based generative model question deduplicaiton plays an important role in grouping these similar questions.
A simple question-answering pipeline consists of three main stages. First, a large number(for example, a thousand) of possibly relevant documents to a given question are retrieved from acorpus by a standard mechanism, such as BM25. In the second stage,passage re-ranking, each of these documents is scored and re-ranked by a more computationally-intensive method. Finally,the top ten or fifty of these documents will be the source for the candidate answers by an answer generation module.
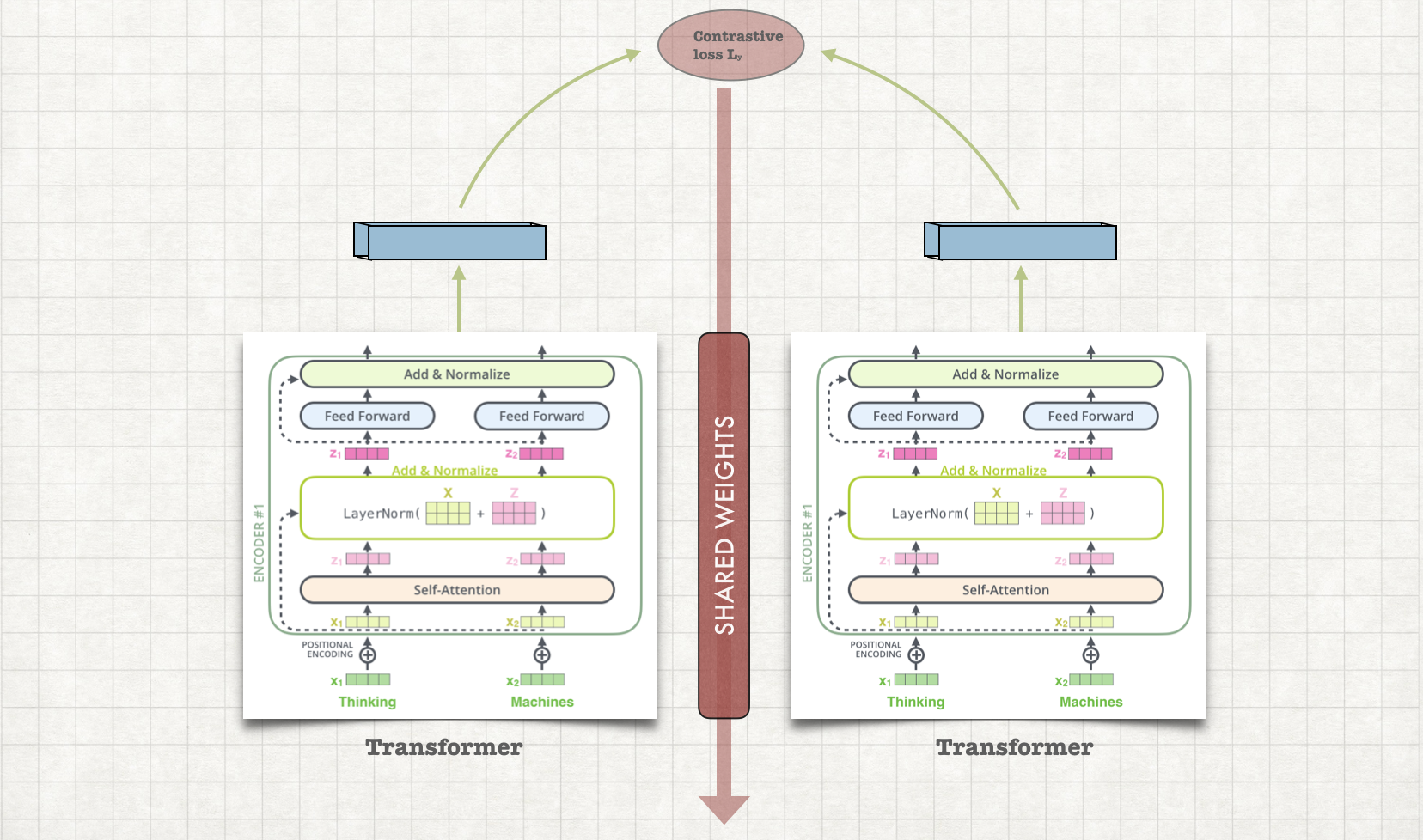
The job of the ranker is to estimate a scores of how relevant a candidate passage is to a query. We use transformer as our ranker
Request question deduplication demo
This model uses Siamese architecture to rank passages for a question. This model is tightly coupled with BM25. A large corpus of documents are ranked for a query using BM25. A selected candidate set among these ranked documents are re-ranked using passage ranking.
Abstractive summarization has been studied using neural sequence transduction methods with datasets of large, paired document-summary examples. However, such datasets are rare and the models trained from them do not generalize toother domains. In this neural model architecture, documents (product or business reviews) with no summaries provided are summarized using unsupervised abstractive summarization.
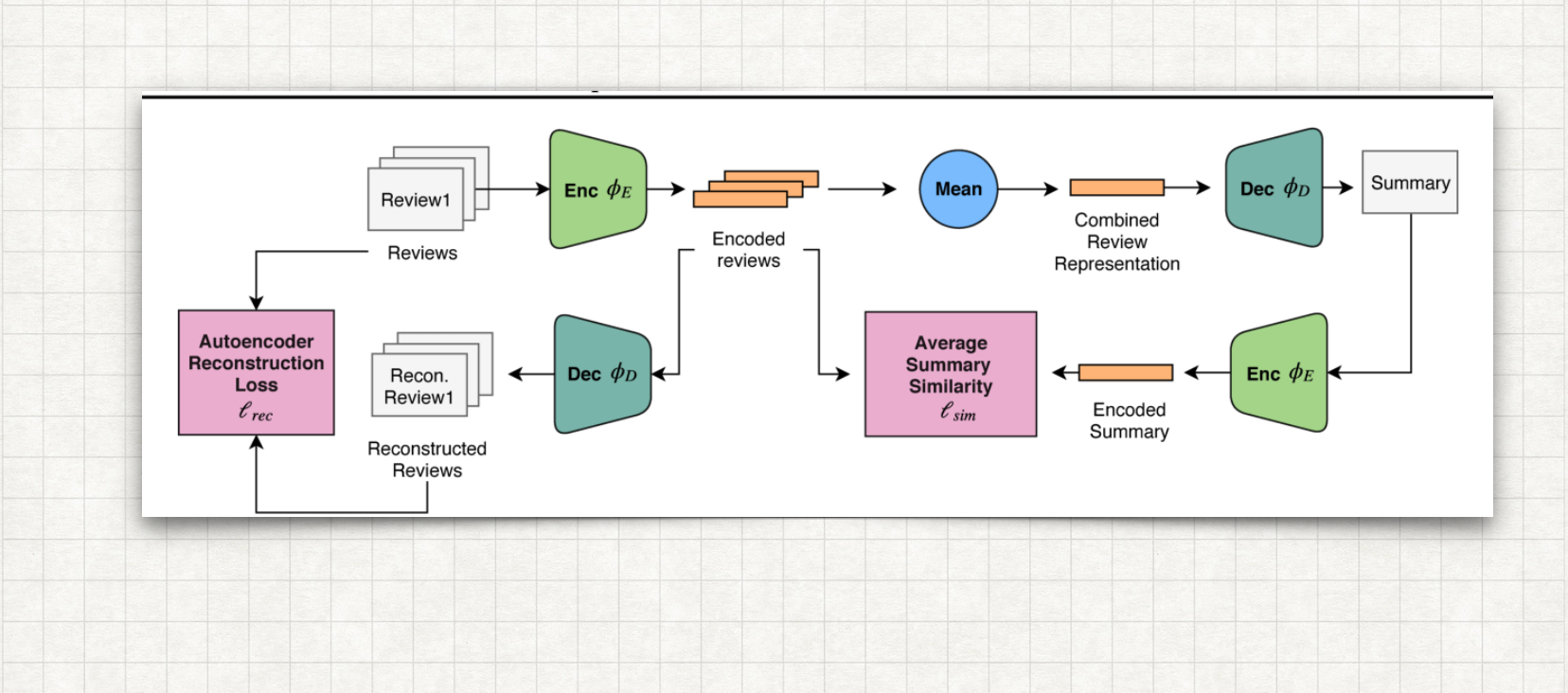
This project contains auto-encoder where the mean of the representations of the input reviews decodes to a reasonable summary-review while not relying on any review-specific features.
Unsupervised abstractive summarization demo request
The standard approaches to neural abstractive summarization use supervised learning with many document-summary pairs that are expensive to obtain at scale. Unsupervised abstractive model address this limitation, for multi-document summarization.
How can we perform efficient inference and learning in directed probabilistic models, in the presence of continuous latent variables with intractable posterior distributions, and large datasets? This model uses a stochastic variational inference and learning algorithm that scales to large datasets and, under some mild differentiability conditions, even works in the intractable case.
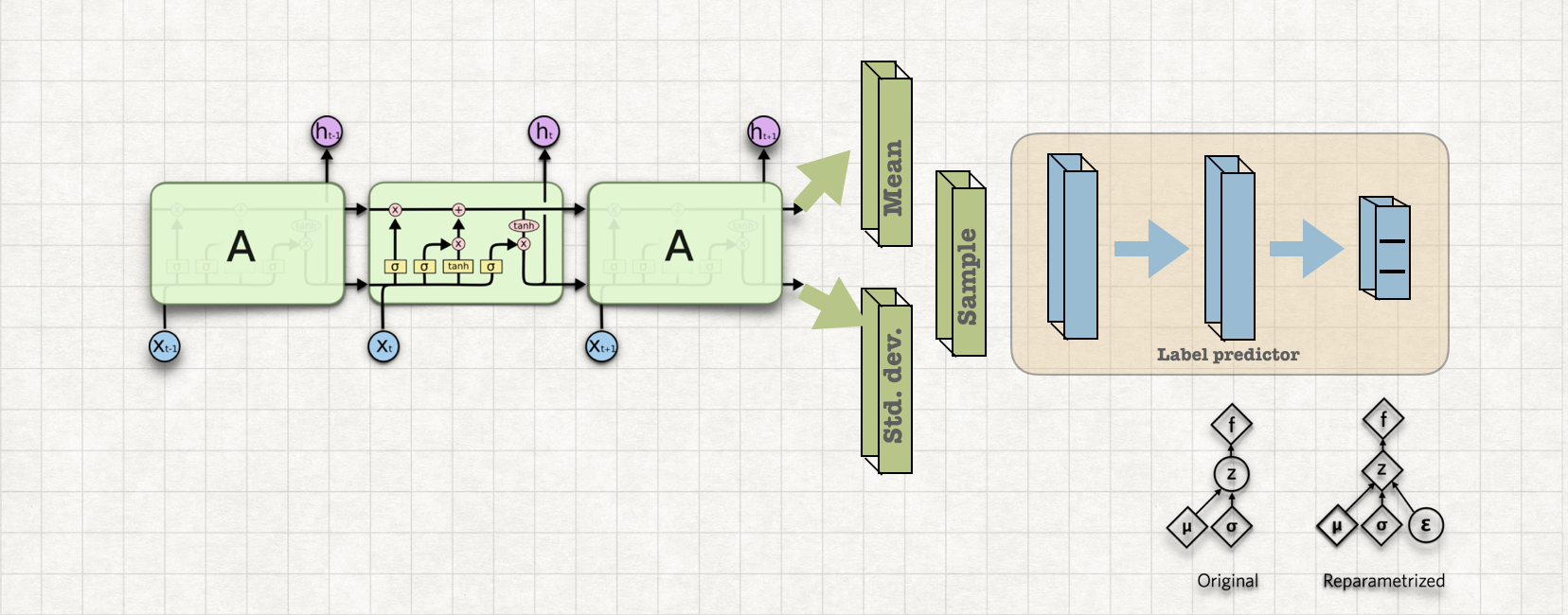
In order to train this model we used youtube video dataset. From which audio spectrogram is extracted and Variational auto encoder is trained. Basic ResNet architectures are used to incorporate encoder and decoders in variational auto encoders.
Gender identification using speech
Identifying the gender of the speaker is one of the popular use case for many busineses. There are already labelled datasets are avaliable but these datasets are language specific and creating labelled dataset for every language would be expensive. Hence this unsupervised approach would help to identify the gender of the speakers.
Information retrieval (IR) is the activity of obtaining information system resources that are relevant to an information need from a collection of those resources. Searches can be based on full-text or other content-based indexing. Information retrieval is the science of searching for information in a document, searching for documents themselves, and also searching for the metadata that describes data, and for databases of texts, images or sounds.
Voise indexed Video Search Engine(VOISE) is the first video opnion search eangine. Information retrieval and Knowledge graphs are the key components of this world opinion search engine.
Request Information retrieval demo
This information retrieval system incorporated on top of knowledge graph and uses elasticsearch, passage ranking model in order to serve the customer requests. IR systems compute a numeric score on how well each object in the database matches the query, and rank the objects according to this value. The top ranking objects are then shown to the user.
The Knowledge Graph is a knowledge base which uses attributes, keyphrases and named entities and its services to enhance its search engine's results with information gathered from a variety of sources. The knowledge graph is also used to catalogue the inhouse data and analyze this data.
This knowledge graph is built on top of the DBpedia knowledge graph. Identifying the named entities present in the text, extracting an entity subgraph from DBpedia and aggregating these subgraphs in order to create knowledge graph and server information retrieval requests using this knowledge graph.
Video insight knowledge graph with Deep walk neural network for cateloging and indexing the video insights for eComerce and non-eComerce pages, integrated with Information retrieval system to server user queires.
Passage retrieval is the determination of the degree of relevance of blocks of text, namely passages, comprising a document. Rather than determining the relevance of a document in its entirety, passage retrieval determines the relevance of the individual passages.
To index video opinions, the first step is to identify those opinions and these opinions are identified using passage retrieval or snippeting model. The model uses enhanced topic modelling such as LDA perplexity to identify the number of topics and NMF to retrieve these topics or opinions from the videos.
Request for Snippeting model demo
Every social media video mostly consists of relevant part and irrelevant content. To differentiate this relevant portion from the irrelevant, snippeting model would be the better choice.
All these models are used in the e-commerce Intelligence Platform. The pipeline architecture is shown as below: