How do I do it?
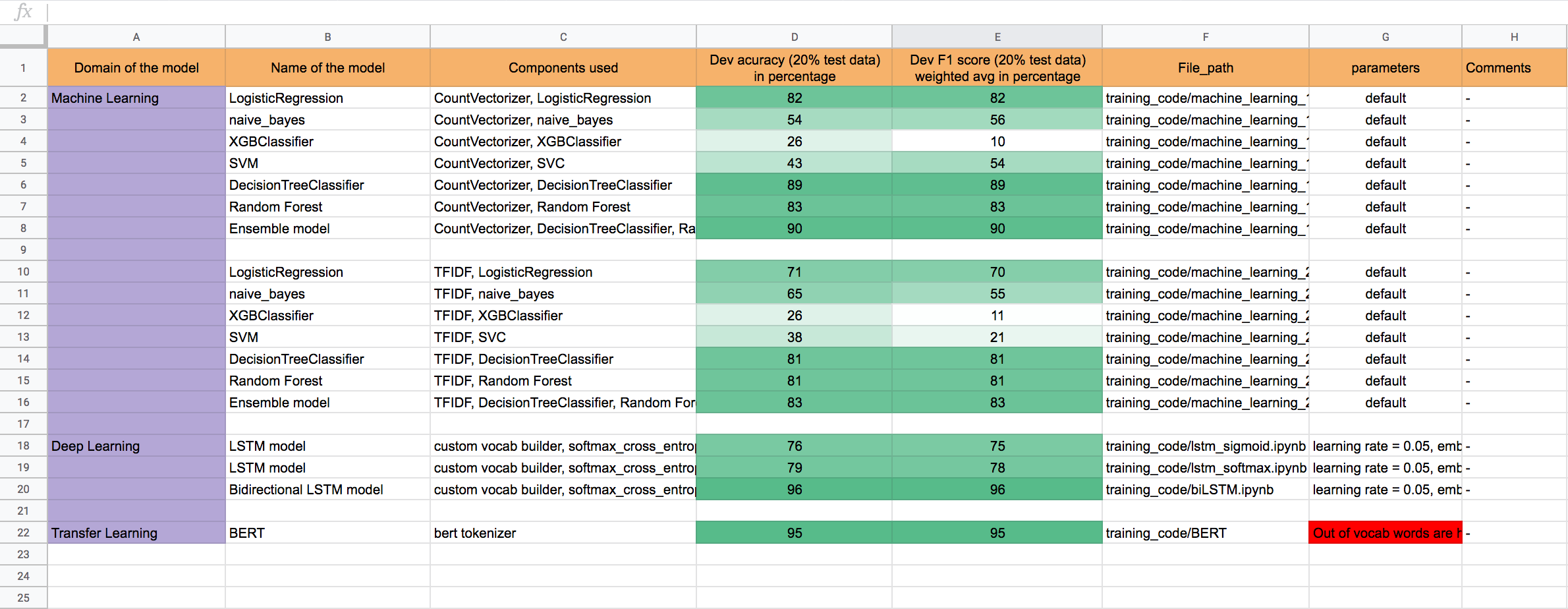
In order to rank candidate profiles for a given job description, extracting skill set from job descriptions and resumes becomes more important task. This information can also be used in competitor behaviour analysis
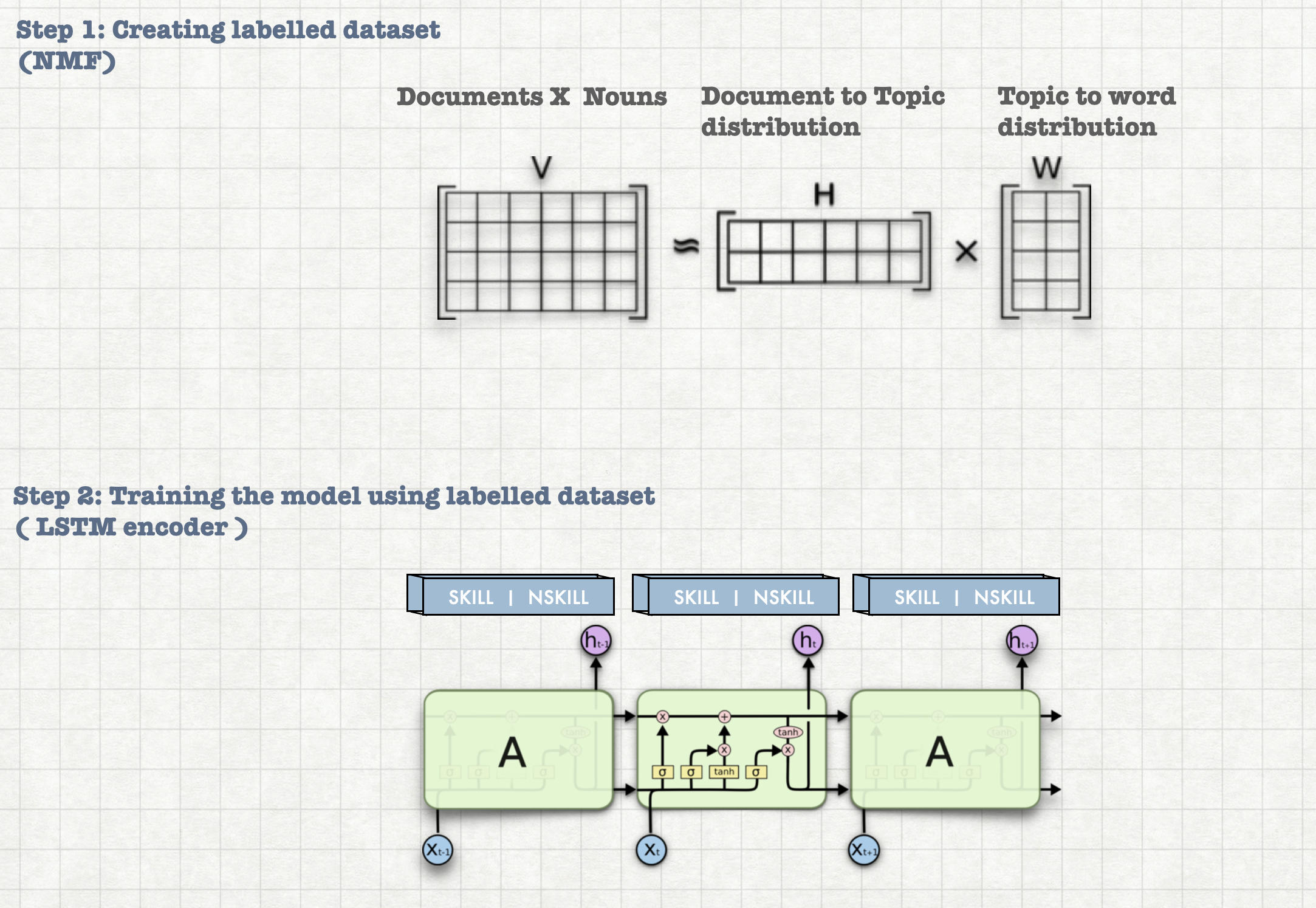
To overcome the lack of the labelled dataset (like 'Java' is an skill set in the job description : "we are looking for java developer") and the amount of effort involved in manual labelling the proposed method uses an unsupervised topic modelling technic inorder to label the dataset. Once the labelled dataset has been created, LSTM based sequence labelling model is trained to identify the skill sets present in the job descriptions.
This model can be used to identify the skill sets present in both job descriptions and candidate's resumes For example: Given a job description "candidate should know java and c++". It will identify java and c++ as skill-sets.
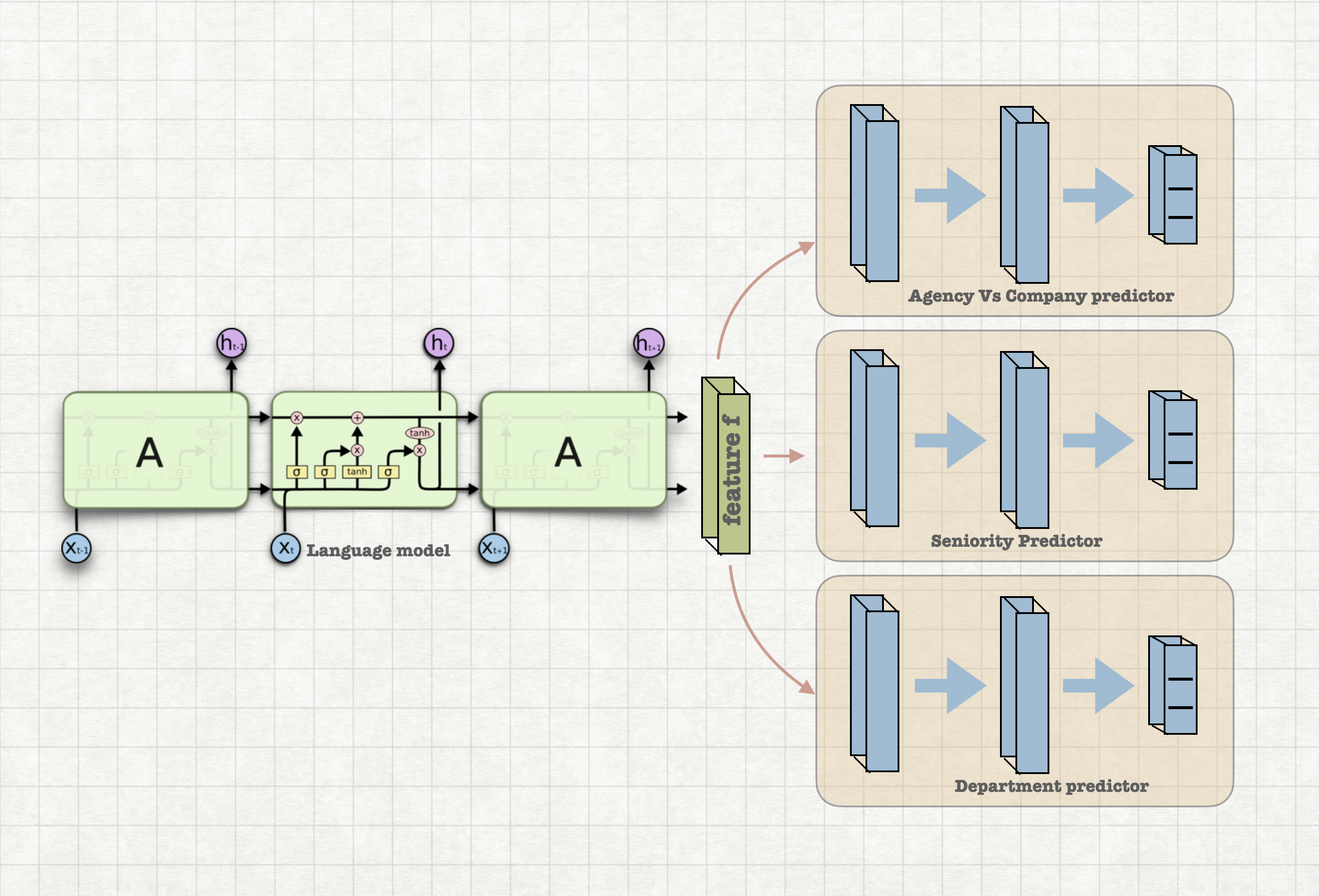
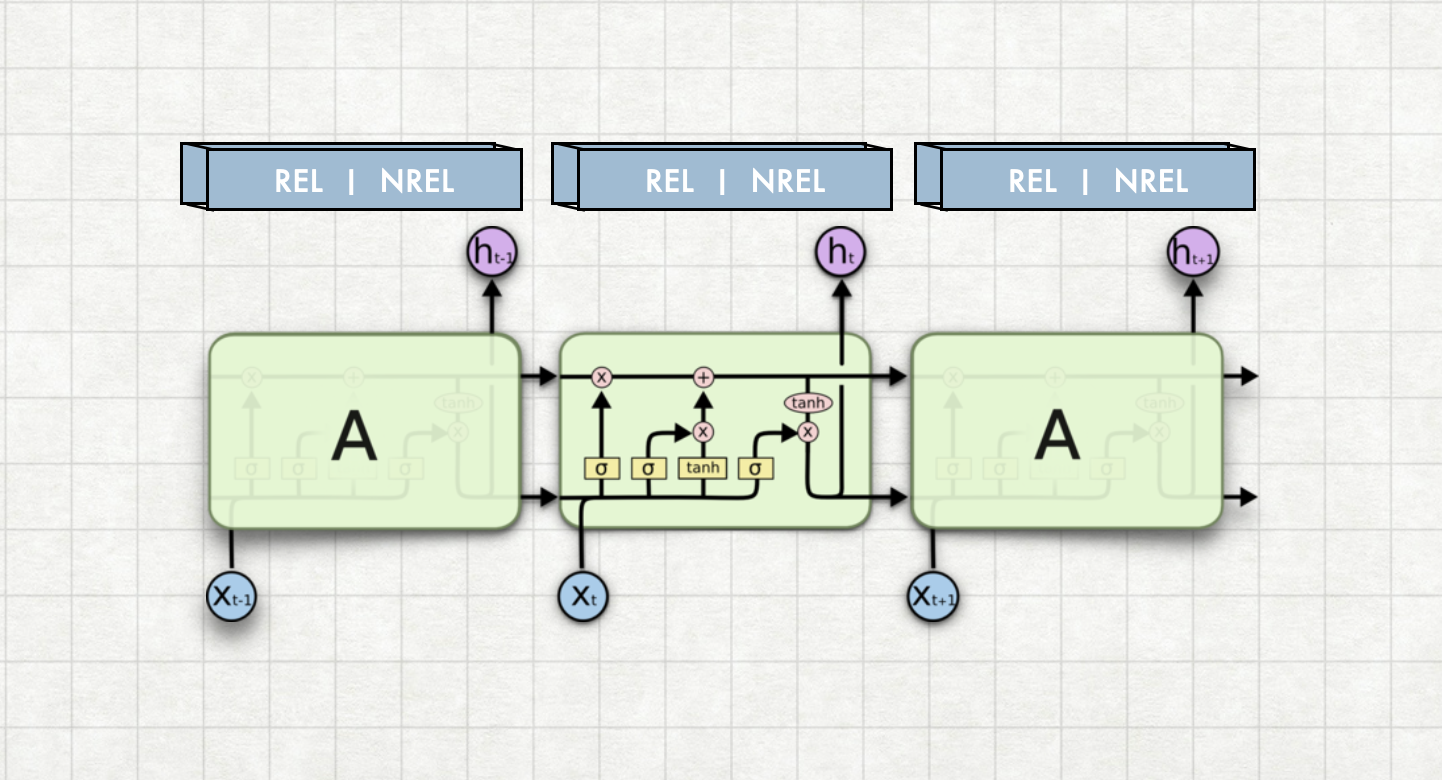
Categorising the job description based on whether it has been posted by the company itself or an agency. Job descriptions often will provide information about whether they are posted by the company itself or the company has asked some third party recruiting agency for the talent hire.
Agency vs company job posting demo
A language model is trained using all the job descriptions. This language model is finetuned to categorize whether the job profile is posted by an ageny or the company itself.
Removing the irrelevant information from the job titles in order to standardise the field. Denoising auto encoder is one of the popular architeture usually used in order to remove the noise from the data.
Bidirectional LSTM based denoising auto encoder is trained using job titles. During the training we introduce noise to the job titke at the encoder end and we try to reconstruct the original job title that do not have any noise. Architecture uses reconstruction loss function
This model is based on denoising auto encoder. Model uses reconstruction loss function. Training data is created using data augumentation technic
Job descriptions have features like experience requirment, salaries which can be used for competitor behaviour analysis and also for candidate profile ranking. Model is trained similar to NER tagger. Each token in the job description is marked under one of the three categories. Those are: experience, salary and currency
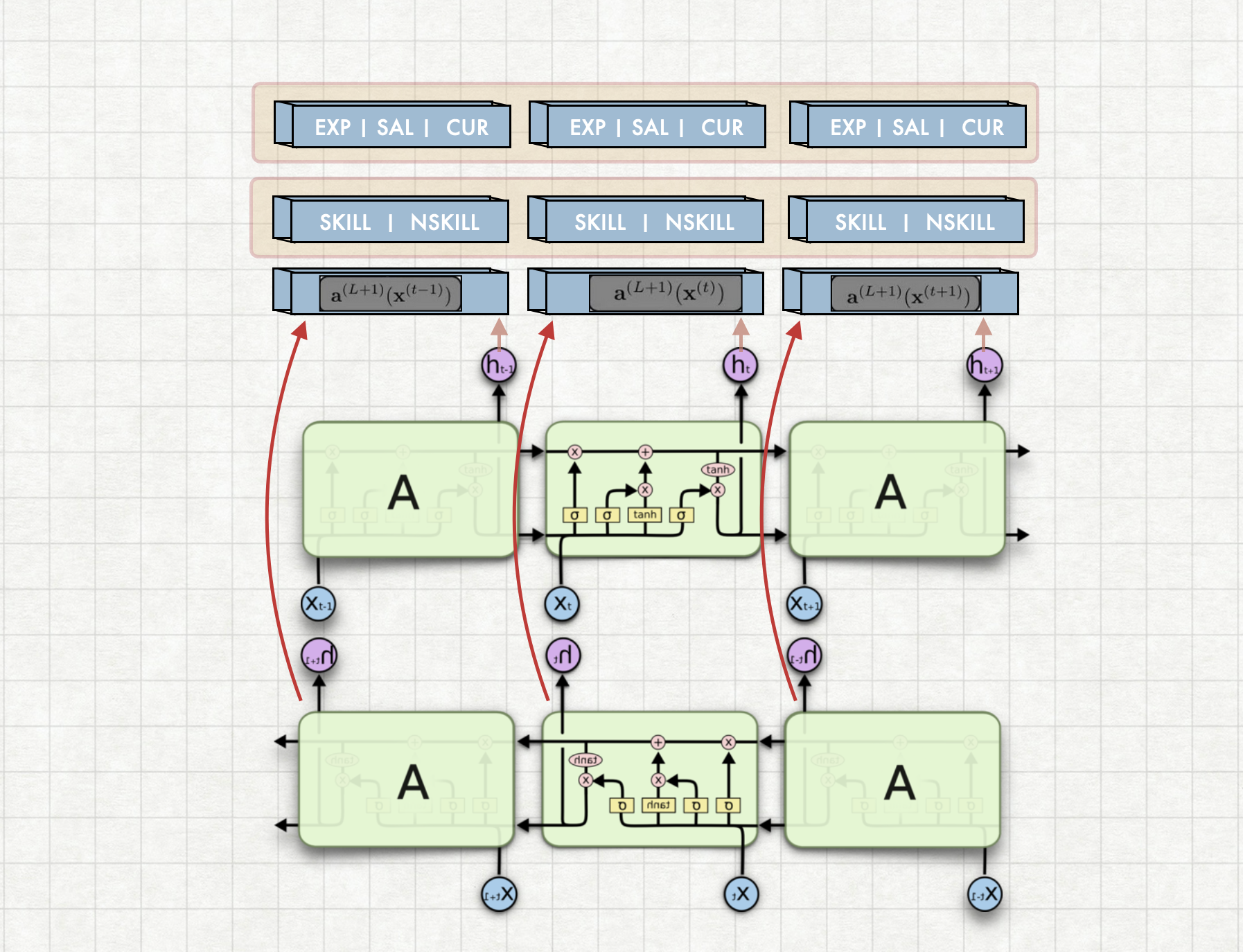
Experience, salary and currency Extraction demo
A language model is trained on job descriptions. On top of this language model we have fully connected layer which convolutes over each token to classify as experience, salary and currency. This is a multi modal architecture which is also used for job profile categorization
Job profiles can be categorized into various categories like engineering, human resource, legal etc.. This categorization helps to enrich the data and organise the data. Classification model is trained using traditional Bidirectional LSTM which is pretrained as language model
Labelled dataset is created by crawling websites like naukri and indeed. In these websites job postings are already organised under categories.
Department categorization demo
A language model is trained on job descriptions. On top of this language model we have fully connected layer which classifies the latent representation into multiple categories. This is a multi modal architecture which is also used for job sequence tagging tasks like skill set extractio etc
Understanding seniority level from job descriptions would help to rank candidate profiles for the job description and also this is very helpful for competitor behaviour analysis. This is solved as classification task on pretrained language model
Labelled dataset is created by key word search and data is augumented with technic like back translation in order to remove the bias from job descriptions
Seniority level prediction demo
A language model is trained on job descriptions. On top of this language model we have fully connected layer which classifies the latent representation into multiple levels. This is a multi modal architecture which is also used for job sequence tagging tasks like skill set extractio etc